Overview
EPM Automate is an Oracle provided command line interface which is used for interfacing with Oracle Cloud EPM applications. These applications expose REST API endpoints for consumption to accomplish a wide variety of activities. (data loading, user management, maintenance, rules execution, etc., etc., etc.) The EPM Automate utility allows users to consume the REST API endpoints without having to write writing code. This is useful for application administrators and power users who wish to perform certain activities without having to navigate the applications graphical user interface. The utility can also be utilized by automation processes to reduce technical debt/maintenance overhead since it abstracts the API details.
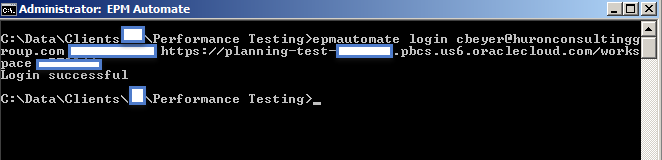
Using EPM Automate is relatively simple as you just download/install the utility, on a Windows or Linux system, and issues commands via the command line. Commands are issued one after another in the necessary sequence to perform a particular task. In the example below, I am connecting to an EPM Cloud application, requesting the value of a substitution variable, and then logging out of the application.
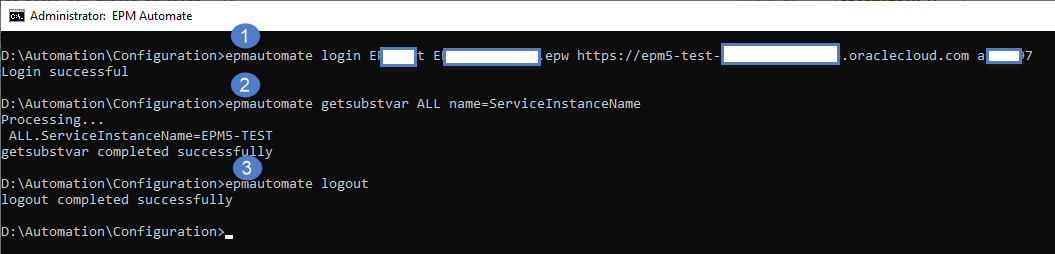
After logging into the application, you can run as many individual commands as you would like and you can leave you ‘session’ open for some time w/o having to provide authenticate again. Even though the underlying API calls are executed separately, and you are not providing credentials for each command issue, the EPM Automate utility is maintaining state behind the scenes.
While this approach is convenient for the user, it is important to understand how this is being accomplished as misuse can result in potentially serious issues! The purpose of this post is to educate you on how EPM Automate State Management behaves and how to avoid any serious issues based on its design. Additionally, I’ll provide some future update thoughts which could address the concern raised here.
State Management
State Management is accomplished through a text file called .prefs. This file contains all of the relevant information that EPM Automate requires to communicate & authenticate with the REST API. The file is created after you successfully execute a ‘login’ command in EPM Automate.
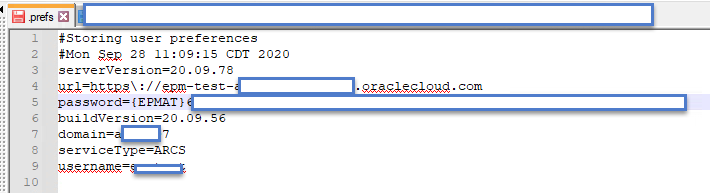
In the early releases of the utility, Oracle stated that you should not run more than one instance of this utility at the same time. While they didn’t elaborate as to why, the issue revolved around the .prefs file. While they have made updates to the application to help address the issue, there are still some gaps which could lead to undesirable consequences.
The (mostly resolved) Issue
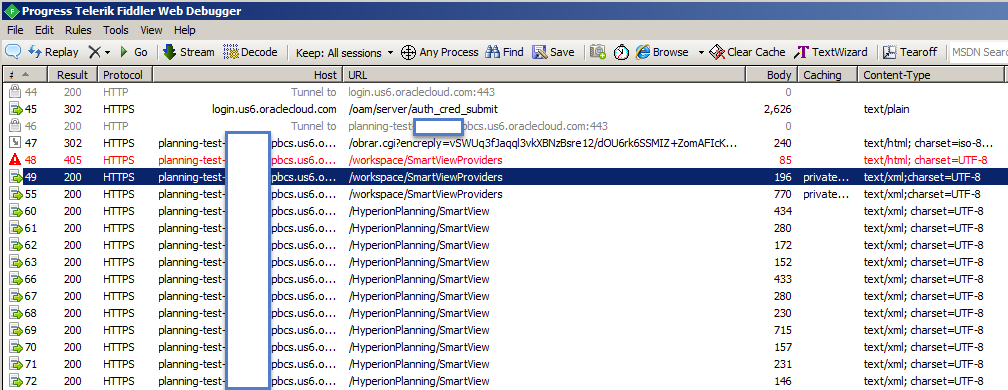
The issue with the .prefs file occurs when you have more than one instance of EPM Automate concurrently in use on the same machine. Originally, the .prefs file was placed in a fixed folder meaning that all instances would be reading/writing the same file and the last successful login attempt by any user on the machine would overwrite the others! If those sessions were working against the same application, not a big deal; however, if the sessions were interacting with different applications, this would be bad. The best movie analogy would be Ghostbusters’ “DON’T CROSS THE STREAMS!”

Since the original version of EPM Automate, they have adjusted this logic to allow for concurrent execution by different users. To accomplish this, the .prefs file is moved under a hidden subfolder which reflects the logged on user’s information.
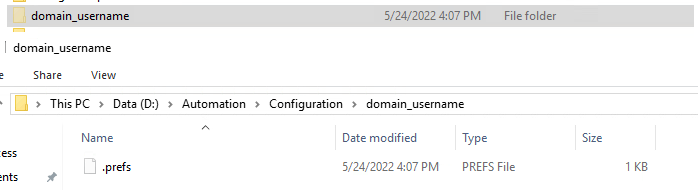
By keying off of the username, this ensures that separate users will not have a collision and can operate safely.
But what happens if the same user wants to be super-efficient and do work on two different Cloud EPM applications concurrently? (it will depend, based on how careful you are!)
Crossing the Streams, for Science!
To demonstrate what could happen, we will open two separate Command Windows and just jump right into issue EPM Automate commands.
Before issuing EPM Automate commands, I’ve added a global substitution variable “ServiceInstanceName” which will hold the service instance name to two FCCS applications.
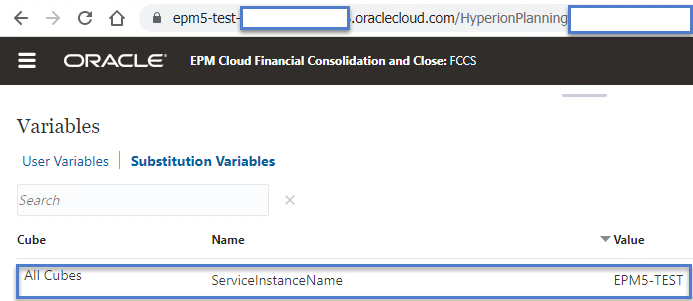
After creating the substitution variables, we will connect to one application at a time and query the substitution variable to see what we get
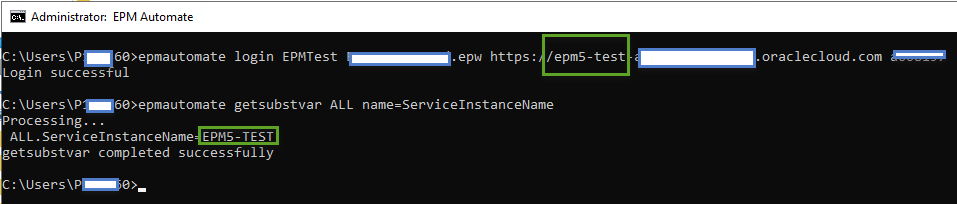
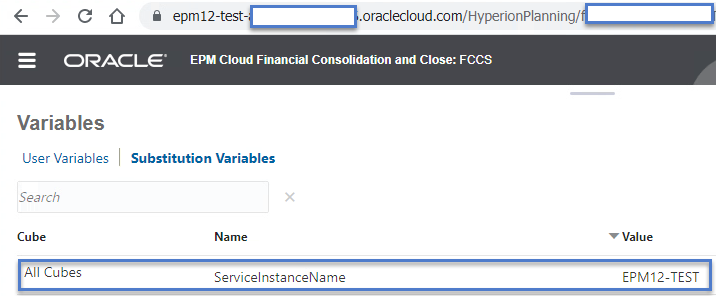
Next, let’s do the same thing for the second server:
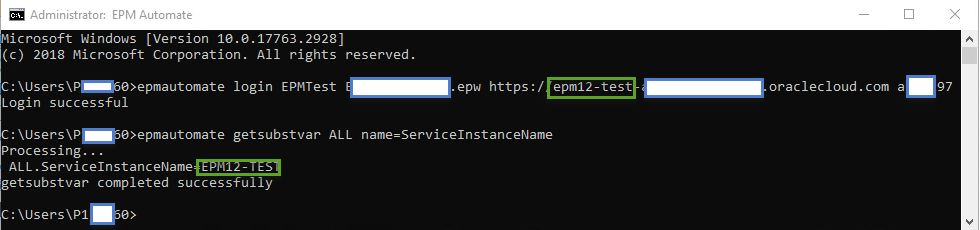
Now, let’s go back to the first window and query the variable again.
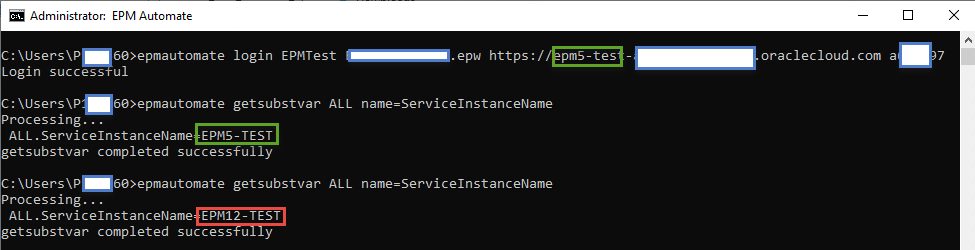
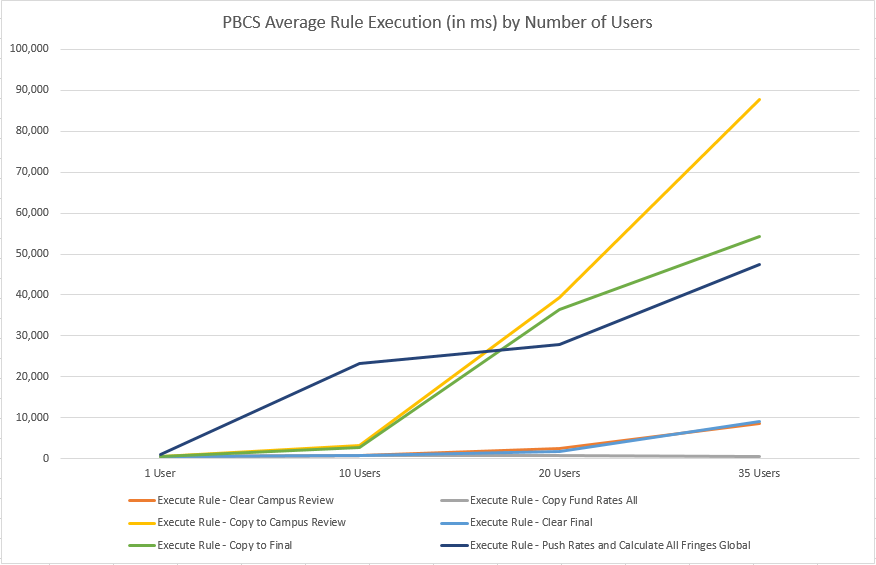
As you can see above, running two concurrent processes as the same user can lead to some undesirable results. While my example is simply reading a variable, imagine what would happen if you logged into a second application and triggered a wipe/reset of the 1st? Oops!
Easy Workaround
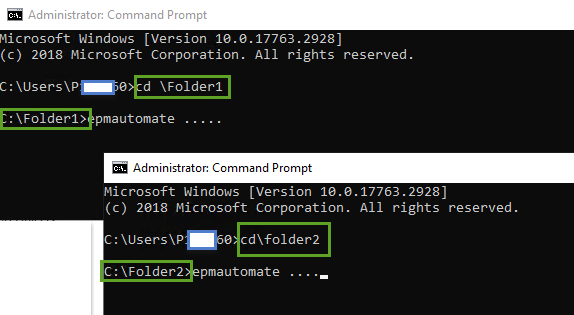
Fortunately, there is an easy workaround. Before starting your EPM Automate sessions, ensure that you are working from different folders and all will be fine since the .prefs files will be created in different locations.
Future Update Thoughts
To fully prevent this issue from impacting interactive users, EPM Automate could append the Process ID (PID) to the folder name which houses the .prefs file. This would ensure that each & every command window has a distinct folder/file.
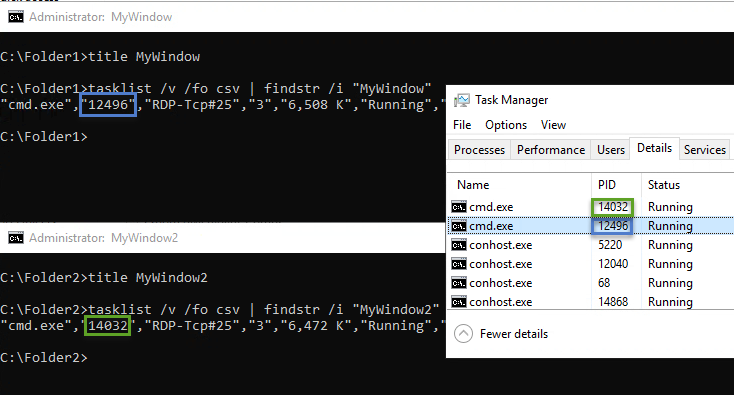
While this would be a quick/easy fix for interactive users, this would create a potential headache for anyone who is using EPM Automate in a non-interactive manner if EPM Automate commands are being issued in separate sessions. (e.g., AutoSys, Control-M, etc.). To address this, Oracle cloud add an optional command line parameter (“prefsfile”) to allow for explicitly setting the location of the .prefs file.





 .
.

 NOTE: This file may not be visible depending on your file folder view settings.
NOTE: This file may not be visible depending on your file folder view settings.