Recently I was asked if I could recover some data from some old 5 1/4″ floppy disks. As I kept my old 8086 computer laying around “just in case”, I was more than happy to oblige! I took the disks and began my challenge laden journey to get the data into a modern system.
Bringing ‘ole faithful back to life
After a quick search of my electronic scrapheap, I located my first IBM-PC compatible computer that I ever owned, an Epson 8086! Like the Millenium Falcon from Star Wars, it may not look like much, but it has it where it counts! (e.g., it has a working 5 1/4″ disk drive!) For those who are interested, here are the specs to this late 80’s powerhouse:

Epson Apex
CPU : Intel 8086 Processor, no Math Co-processor
Speed : 4.77 Mhz w/ 10 Mhz 'Turbo' Mode
Memory : 640 KB Conventional RAM, no Extended or Expanded RAM
Video : CGA Graphics - 256 colors in text mode, 4 colors @ 320x200 graphics resolution
HDD : 20 MB RLL Encoded Hard Drive
Floppy : 360 KB 5 1/4" Drive
Ports : 9-Pin DIN Keyboard, 25-Pin Serial, 25-Pin Parallel
Just like the Millenium Falcon; however, I had performed a slight modification to this computer, a Microsoft Mach 20 add-on board!
Microsoft Mach 20 Board
CPU : Intel 80286 Processor
Speed : 8 Mhz 'Turbo' ("Equivalent to 12 Mhz 80286's of the day")
Memory : 512 KB RAM, expandable to 3.5 MB
The board works by replacing your 8086 Processor with an special adapter that connects the Mach 20 board to the computer’s motherboard. The additional RAM is recognizable as Extended (first 384 KB) and Expanded (remainder) by including HIMEM.SYS and EMM386.SYS in the MS DOS config.sys file.
Why am I mentioning this board you ask? It was the first obstacle between me and my data!
Well I guess the 20, in Mach 20, refers to its lifespan….
I hooked up the keyboard, the monitor, and power cables and hit the Hyperdrive. (Power button) The lights in my workout room momentarily dimmed and the screen flickered with a BIOS self test, perfect! The memory test systematically ran through the memory: 64 KB, 128 KB, 256 KB. Just as I thought things were going well, failure! The screen froze at 256KB and then the screen went dead. I shrugged it off as a fluke and punched the button again. Once again, the memory test began: 64 KB, 128 KB, 256 KB, 320 KB, 384 KB. Once again, I was met with a resounding failure as it froze again. I looked over the internals of the computer and at initial glance everything appeared to be in order. As I started feeling the connections, I discovered that the Mach 20 CPU connection cable felt suspect. On a hunch, I held the cable down and hit the switch again. 64 KB, 128 KB, 256 KB, 320 KB, 384 KB, 448 KB, 512 KB, 576 KB, 640 KB! Success! I quickly shut off the machine and placed one of the our epoxy coated 5 LB dumbbells on the connection. With the Mach 20 situation addressed, I was on the fast path to getting that data….. or not …….
Anyone have a 9-PIN DIN Keyboard laying around? I didn’t think so ……
As I restarted the computer and watched the memory test complete, I was greeted with the next obstacle: BIOS test failures! The first error was a lovely 301 Keyboard error. As the picture at the beginning of this post should attest, the keyboard has seen better days and it was very, very unhappy. As I don’t keep spare DIN keyboards laying around and it was ~ midnight, I didn’t have any options other than to find a way to make it work. After disassembling the keyboard, I found significant corrosion on the connectors. I cleaned the corrosion and reassembled what was left of the keyboard. Fortunately, this was sufficient to allow the BIOS keyboard test to pass! Later into the process of recovering the data, I discovered that some buttons didn’t work on the keyboard which made typing difficult, but not impossible. (HINT: ALT + ASCII code will put a character on the screen)
Floppy Drive Cable, Where Art Thou?
After resolving the keyboard failure, I was presented with yet another BIOS test gift, 601 – Diskette Error. As the whole point of this exercise is to read data from the floppy disk, this error was especially cringe worthy. After staring at the screen momentarily in a mixture of disbelief and annoyance, I took another look at the cabling and discovered a likely explanation for the problem: there wasn’t a floppy drive cable! Even though it had been over a decade since I last used this machine, I tried to come up with a reason why the cable would be gone and came up completely blank. (still don’t know) I searched through my bin of spare cables; however, this was a cable I didn’t have since these cables are nothing like current drive cables. Defeated, I retreated to my laptop in search of a cable. In an amazing stroke of luck, Fry’s electronics stocks these cables and I picked two up in the AM. (I have no idea why they stock this cable, but I’m sure glad they had it!) I connected the cable, fired up the machine, and all BIOS tests passed. The machine booted up DOS and things were finally falling into place. I inserted the 5 1/4″ floppy, type A: to access the drive and ……..
exercise is to read data from the floppy disk, this error was especially cringe worthy. After staring at the screen momentarily in a mixture of disbelief and annoyance, I took another look at the cabling and discovered a likely explanation for the problem: there wasn’t a floppy drive cable! Even though it had been over a decade since I last used this machine, I tried to come up with a reason why the cable would be gone and came up completely blank. (still don’t know) I searched through my bin of spare cables; however, this was a cable I didn’t have since these cables are nothing like current drive cables. Defeated, I retreated to my laptop in search of a cable. In an amazing stroke of luck, Fry’s electronics stocks these cables and I picked two up in the AM. (I have no idea why they stock this cable, but I’m sure glad they had it!) I connected the cable, fired up the machine, and all BIOS tests passed. The machine booted up DOS and things were finally falling into place. I inserted the 5 1/4″ floppy, type A: to access the drive and ……..
Abort, Retry, Fail?
Anyone who has worked in DOS knows this message and the fear it creates as you realize your data is probably corrupt and gone forever. While I set early expectations that the 5 1/4″ disk may not be recoverable due to its age, the disk was well stored and I was really hoping to get this data. I wasn’t ready to let it die on the operation room table! (actually my workout room floor, but who is keeping track…) I futilely tried to access the drive repeatedly. Each time I was met with the same cold message. I looked at the clock and almost called the time of death on my data recovery effort, but I wanted to try one more thing. Looking very closely at the disk, I noticed that it didn’t appear to seat entirely into the disk drive. Even though the locking mechanism closed, the disk drive started up, and it sounded like it was working, it didn’t look quite right. I used my left hand to push the disk into the drive farther and then tried to access the disk again. Success! Treating the disk as if it were an self destructing Mission Impossible message, I quickly copied the entire contents of the floppy disk to the computer’s hard drive. I basked in the successful data copy for a few moments and then realized that my job wasn’t close to done.
Congratulations, you’ve moved your data from an obsolete 5 1/4″ disk to an obsolete computer, now what?!?!?
While I was able to read the data of the floppy successfully, I still had to find a way to get it to the person needing the data. This antique didn’t have an Ethernet card (or software to run it) so I couldn’t email, FTP, or directly move the data across a network. The machine didn’t have a 3 1/2″ disk drive which could be more useful. I didn’t even have a modem. There were two options that came to mind:
- Transplant the hard drive into a more modern computer – While at first this may seem like a dead end, this is actually a very viable option. Even though the hard drive is an older format which a newer computer wouldn’t recognize, I could move the controller card AND the hard disk into a newer machine with ISA slots and it would work! (I’ve done it once before) I grabbed the oldest/modern machine I had laying around, an HP Pentium based desktop, ripped it open and …….. *NO* ISA slots. Unfortunately, it was just new enough that it had PCI; therefore, I would not be able to move the hard drive and needed a Plan B.
- Transmit the data over the Serial / Parallel ports to another computer – Thinking back to my old DOS days, I recalled a program built into the later versions of DOS that would allow you to send files between computers. After combing through the DOS folder, I located the program: Microsoft Interlink.
My victory was once again short lived as a few realizations set in:
- Microsoft Interlink needs to run on both the host AND destination computers – As newer computers don’t ship with this program, I would need to get it copied over to the destination machine. Of course if I had a way to copy that file, I wouldn’t need the program in the first place……… After a lot of scouring, I found a someone who was hosting the necessary files!
http://www.pcxt-micro.com/dos-interlink.html - Microsoft Interlink needs a “LapLink” or Null modem cable – No problem, I know I have a Laplink cable here somewhere……….. I searched through my spare cable bin and my cable was nowhere to be found. Unfortunately I gave away a large amount of older computer items just weeks before I took on this task and I suspect it was one of the items I gave away. (After all, who would need an old LapLink cable, right?) That’s OK, lets make our own….
Microsoft Interlnk, the gift that keeps on giving!
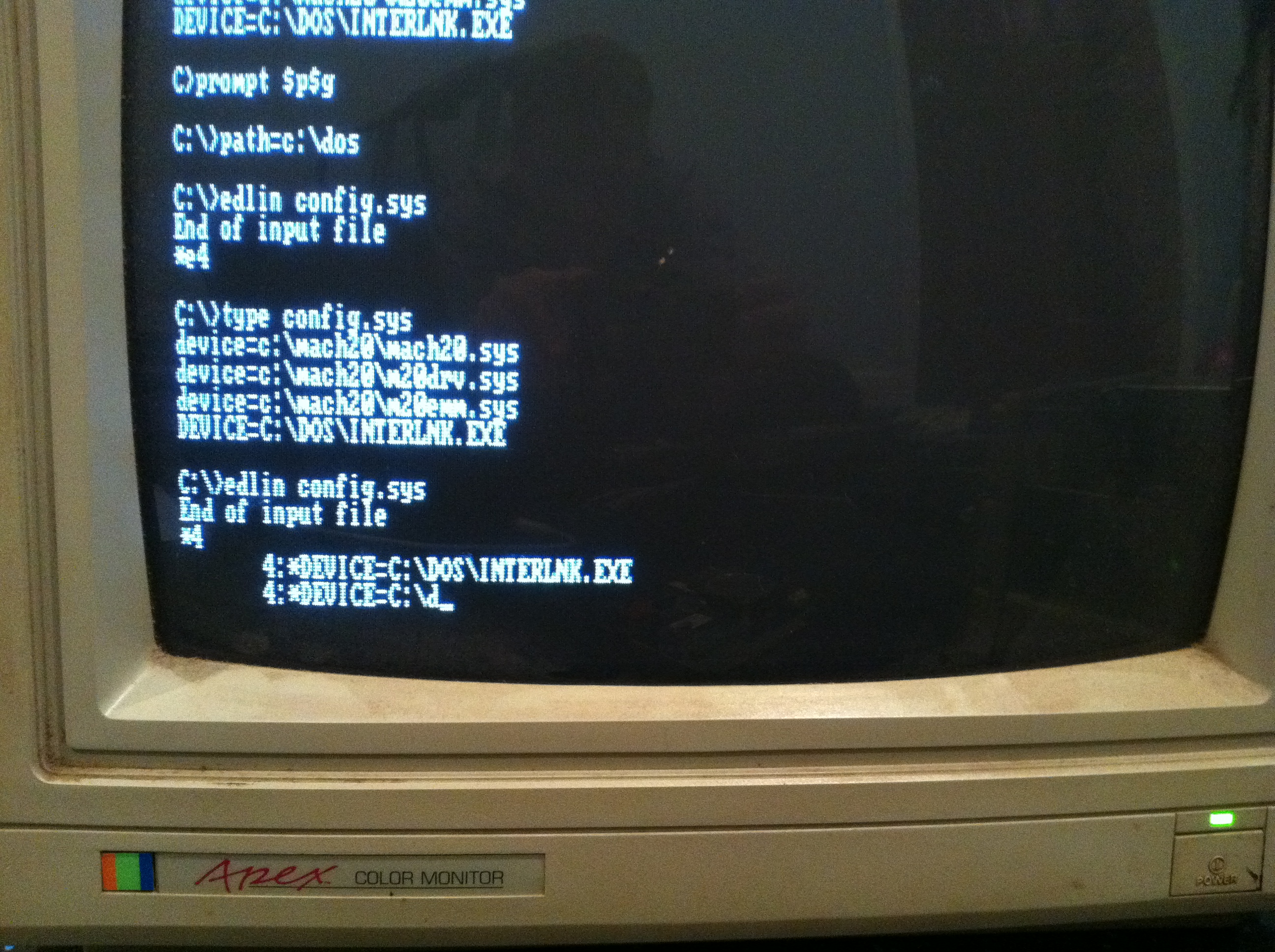
A quick scan of the Microsoft website (http://support.microsoft.com/kb/121246/en-us/), as well as the Interlnk help file, provided all the information necessary to wire up the pins. In a huge stroke of luck, the prototyping cables I use for my circuit work perfectly fit the serial port pins making connecting the machines quick work. The only drawback is since the cables are relatively short, it was a bit of a challenge to hook everything up. With the cables connected to the computers, I turned my attention to configuring the software.
As I alluded to earlier, both machines need to have software running for this to work, the following steps outline what needs to happen:
- Place INTERLNK.EXE and INTERSVR.EXE on both machines
- Update the CONFIG.SYS file to load a device drive as follows:
DEVICE=C:\DOS\INTERLNK.EXE /<ltp|com>:<number> where:
- <ltp/com> – specify LPT if connecting through a parallel port, com if connecting through serial port.
- <number> – is the port number (i.e. If connection to LPT2 / COM2, enter a 2 here)
- Update the AUTOEXEC.bat to call the INTERSVR.EXE program
C:\DOS\INTERSVR.EXE - Ensure the cable is connected between the machines
- Restart the machines

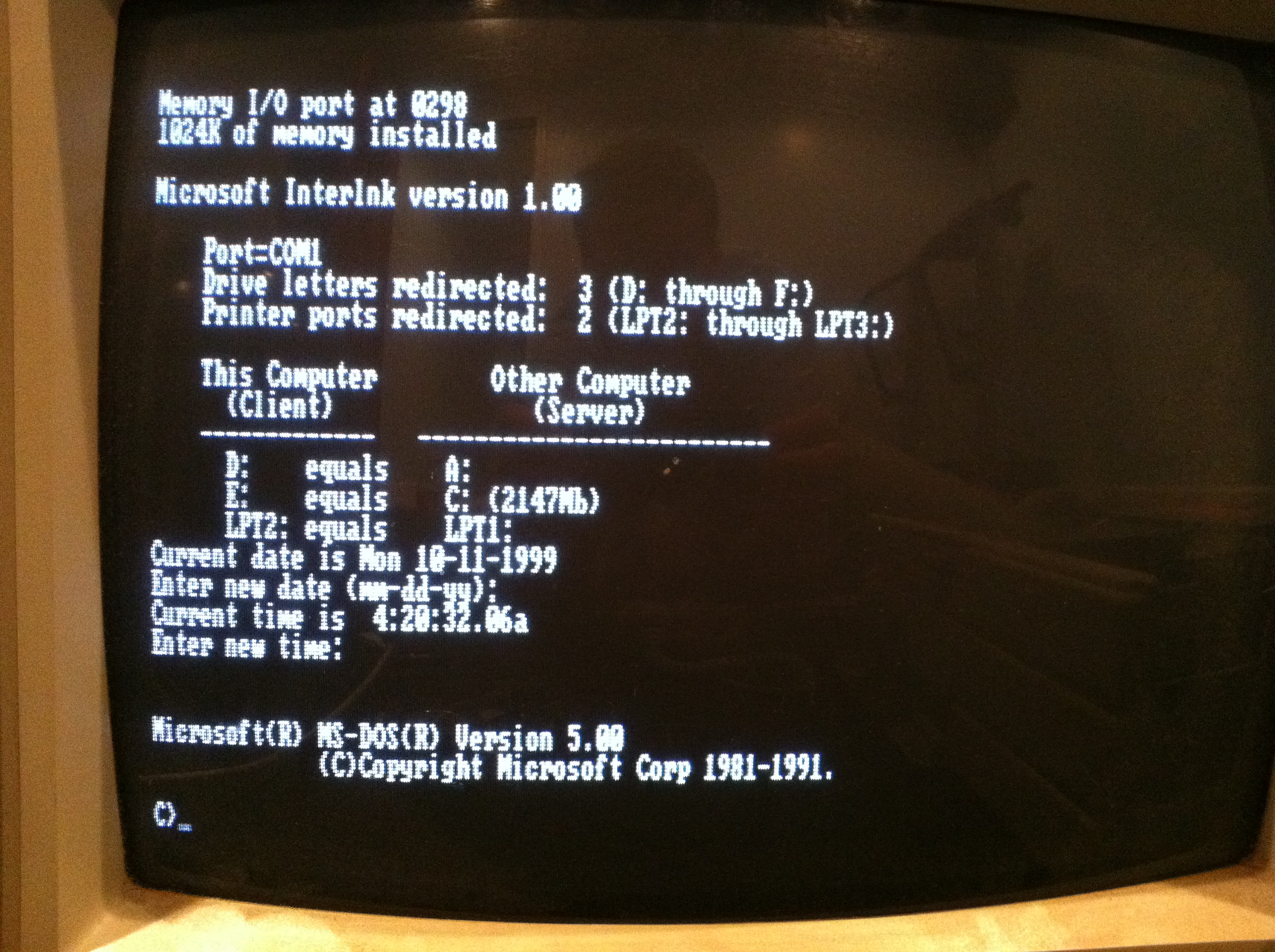
If everything is setup right, during the boot-up process you will see a message indicating that a link has been established and it will assign a local drive letter to the remote system.
Success at last!
After restarting both machines, Microsoft Interlnk loaded and a drive map was established between the two machines. I copied the files over to the newer machine and then used a IDE-USB adapter to connect that computer’s hard drive to my laptop and send the files off.
It wasn’t pretty, but in the end everything worked out and I got to justify keeping my old 8086 around!
Since it is up and running….
After I had successful sent off the files, I went back to the old 8086 to see what was still on the machine. I found a couple of old, but good games that I used to play and some old code I wrote to add mouse support to a BASIC program I was writing. A nice trip down memory lane!